Удобная функция UNNEST в PostgreSQL для работыВсем привет! Решила поделиться тут с вами одной полезной функцией, которую как раз недавно использовала на работе.
У нас есть массив устройств у пользователей. Но если мы хотим:

посчитать устройства
сделать join
агрегировать
считать DISTINCT
то массив нужно разложить в строки.
Представим, что у нас есть данные, где у пользователя несколько устройств лежат в массиве.
Было: 1 строка = массив устройств
Должно быть: несколько строк с пользователем = одно устройство в строке
Сначала создадим это прямо в Python
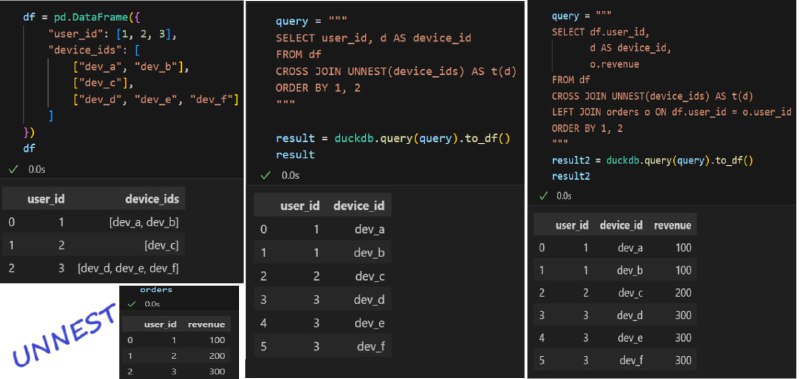
import duckdbimport pandas as pddf = pd.DataFrame({ "user_id": [1, 2, 3], "device_ids": [ ["dev_a", "dev_b"], ["dev_c"], ["dev_d", "dev_e", "dev_f"] ]})
И вот тут-то мы разворачиваем массив через
UNNESTquery = """SELECT user_id, d AS device_idFROM dfCROSS JOIN UNNEST(device_ids) AS t(d)ORDER BY 1, 2"""result = duckdb.query(query).to_df()
Разберем необычную конструкцию
CROSS JOIN UNNEST(device_ids) AS t(d)Что вообще означает AS t(d)?

UNNEST(device_ids) - разворачивает массив
t - имя временной таблицы
d - имя колонки внутри неё
После этого d — обычная колонка, с которой можно работать как с любой другой.
Главное потом случайно не задвоить метрику когда будем соединять таблицу с таблицей заказов, например.
orders = pd.DataFrame({ "user_id": [1, 2], "revenue": [100, 200]})
Теперь делаем join после UNNEST:
query = """SELECT df.user_id, d AS device_id, o.revenueFROM dfCROSS JOIN UNNEST(device_ids) AS t(d)LEFT JOIN orders o ON df.user_id = o.user_idORDER BY 1, 2"""result2 = duckdb.query(query).to_df()
User 1 имел revenue = 100
Но теперь эта сотка появилась два раза!
😱Поэтому нужно быть внимательным и понимать для чего мы это делаем.
❌ Нельзя после этого просто делать SUM(revenue) по этой таблице - выручка продублируется на каждое устройство и итог “раздуется”.
✅ Но зато расшив девайсы и приджойнив user-level выручку мы можем посмотреть её рядом на строках устройств.
💡 Зачем это может быть нужно?
Например:
сколько устройств у платящих пользователей
есть ли различия между single-device и multi-device users
сколько выручки приходится на пользователей с 3+ устройствами
Мы не делим revenue по устройствам. Мы просто используем её как
атрибут пользователя.
P.S Кстати, я перешла на VS Code - мне нравится. Красивый же черный фон, да? Ну и удобно видеть в структуре файлы проекта.