Почему ИИ сдаёт медицинские экзамены на отлично, но проваливается с реальными пациентами
Почему ИИ сдаёт медицинские экзамены на отлично, но проваливается с реальными пациентамиПривет! Меня зовут
Ольга Титова, я работаю AI Product Manager, выступаю за безопасный и этичный подход к ИИ, и каждую неделю делюсь с подписчиками Femtech Force новостями из мира ИИ и здоровья.
На прошлой неделе мы разобрали, что OpenAI предлагает врачам в ChatGPT for Clinicians: бесплатный GPT-5.4, шаблоны для рутины, автоматические баллы повышения квалификации (и трёхуровневую стратегию захвата health AI). Сегодня — обещанный разбор: почему модель, которая знает правильный ответ в 95% случаев, пока не помогает реальным людям.
 Исследование с парадоксальным результатом
Исследование с парадоксальным результатомВ феврале 2026 года исследователи из Оксфорда (Oxford Internet Institute и Nuffield Department of Primary Care) опубликовали в
Nature Medicine крупнейшее на сегодня рандомизированное исследование того, как обычные люди взаимодействуют с медицинскими LLM. Дизайн простой: 1298 участников получили медицинские сценарии и должны были определить, что это за состояние и нужна ли скорая, визит к врачу или достаточно самолечения. Три группы пользовались LLM (GPT-4o, Llama 3, Command R+), четвёртая — контрольная — обращалась к привычным ресурсам: поиску в интернете и сайту NHS.
 Что же получилось?
Что же получилось?LLM, работая без человека, правильно определяли состояния в 94.9% случаев. А участники, использовавшие эти же модели, —
менее чем в 34.5%, то есть
хуже, чем контрольная группа,
которая обходилась без ИИ вообще. По выбору срочности ИИ тоже не помог: разницы с контрольной группой нет.
Выделили две причины сбоя. Во-первых,
люди не давали модели достаточно информации, больше половины первичных сообщений оказались неполными. Во-вторых, даже когда
модель предлагала правильный ответ среди нескольких вариантов, люди не могли его выбрать.
Почему это поднимает вопросы и для HealthBench — бенчмарка от OpenAIИсследователи также сопоставили результаты моделей на стандартном медицинском бенчмарке MedQA (вопросы из лицензионных экзаменов) с результатами взаимодействия с живыми людьми, и оказалось, что корреляции между ними практически нет. Модель,
набравшая 80%+ на экзамене, могла показать менее 20% с реальным пользователем. Даже симуляции с ИИ-«пациентами» (популярный сегодня метод тестирования) не предсказывали поведение реальных людей.
OpenAI оценивает ChatGPT for Clinicians именно бенчмарком — собственным HealthBench Professional,
где он набрал скор 59.0, обогнав реальных врачей. Но бенчмарк измеряет качество текста ответа модели, а не реальное взаимодействие в связке врач-ИИ-пациент.
Что я думаю?Для документации, обзора литературы и шаблонов писем ChatGPT for Clinicians действительно может экономить врачам часы и это уже отлично, учитывая масштаб бюрократического выгорания. Но между «помогает быстрее написать реферальное письмо» и «помогает принять клиническое решение» — огромная разница.

Первое — инструмент продуктивности.
Второе — медицинское изделие, которое должно проходить клиническую валидацию. OpenAI заявляет, что остаётся в зоне первого, но продукт устроен так, что пользователи неизбежно будут уходить во второе.
И главный вывод, который я для себя сделала: дело не только в том, насколько умна модель, а в том, хорошо ли умеем мы с ней разговаривать. Пока, кажется, ответ — «не очень».
@FemtechForce — о технологиях для здоровья женщин
Текст подготовила #ОльгаТитова
Спустя почти год его не диагностировали!!! Спасибо большое! Бесконечная благодарность!

 Предыстория:Моей подопечной 17 лет. Когда она ко мне пришла, то ей ставили сколиоз, и по диагностике, которую я сделала, тоже было видно сколиоз. Снимков не было. Но вот что она пишет мне сегодня:
Предыстория:Моей подопечной 17 лет. Когда она ко мне пришла, то ей ставили сколиоз, и по диагностике, которую я сделала, тоже было видно сколиоз. Снимков не было. Но вот что она пишет мне сегодня:





 Мы в MAX -
Мы в MAX - 

















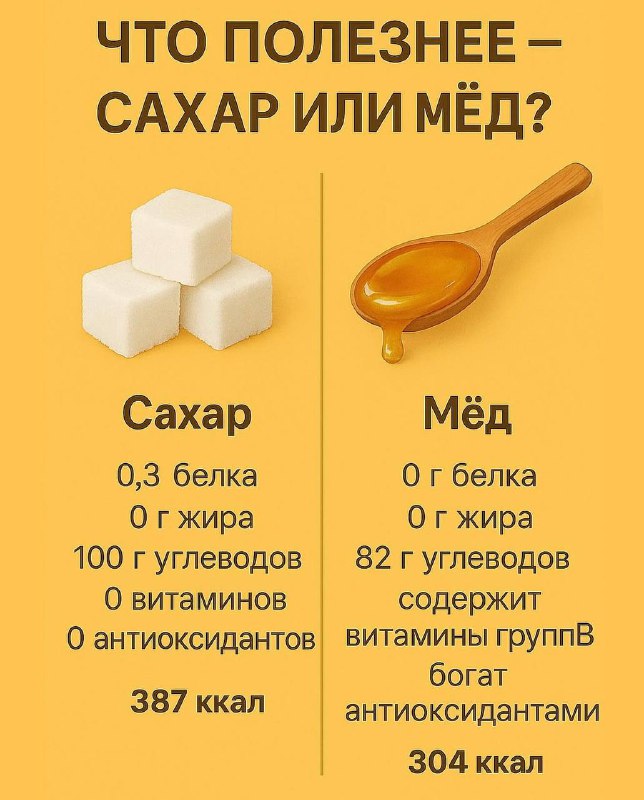
 Сохраняйте себе: такие сравнения помогают делать осознанный выбор каждый день 😌🥑🫘
Сохраняйте себе: такие сравнения помогают делать осознанный выбор каждый день 😌🥑🫘