pip install torch tiktoken
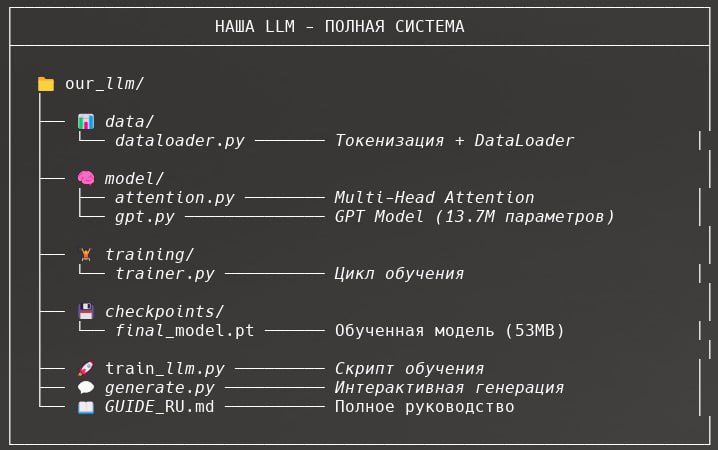
На прошлой неделе собрал свою языковую модель с нуля. GPT-архитектура, 13 миллионов параметров, PyTorch.Нет, не чтобы конкурировать с OpenAI - это было бы тупо.А чтобы наконец понять, как эта хуйня работает изнутри.Почему это важноКогда ты используешь Claude или GPT как чёрный ящик - ты не понимаешь, почему модель выдаёт именно такой результат.Почему галлюцинирует. Почему на один промпт отвечает огонь, а на другой - полную дичь. Почему temperature 0.7 работает лучше чем 1.0.Когда собираешь сам - начинаешь видеть:1/ Attention (механизм внимания) - почему модель "смотрит" на определённые токены, а другие игнорит2/ Temperature - это буквально деление логитов на число, никакой магии3/ Почему контекст ограничен - не жадность OpenAI, а квадратичная сложность attention4/ Как модель учится - просто предсказывает следующий токен, всёЧто я сделалВзял книгу Sebastian Raschka "Build a Large Language Model (From Scratch)" и прошёл первые 5 глав:- Token и Position Embeddings- Multi-Head Causal Self-Attention- Transformer блоки с Layer Norm- Feed-Forward сети с GELU- Генерация текста (greedy, temperature, top-k)Обучил на небольшом тексте (20K символов). За 20 эпох loss упал с 10.5 до 2.7. Модель начала генерить связные предложения.Весь код - ~600 строк Python.Как начать






 Когда человек несколько дней находится в плотной профессиональной среде, обсуждает проекты, решения, ограничения, сравнивает подходы, смотрит на работающие системы, у него постепенно возникает потребность в дистанции. В паузе, в пространстве, где можно не просто переключиться, а собрать для себя главное.Именно поэтому Байкал для меня — часть его внутренней логики. Не потому, что «красиво». Хотя, конечно, красиво. А потому, что сильные выводы не всегда рождаются в аудитории — иногда им нужно пространство, воздух и тишина.Мне вообще кажется, что профессиональная перезагрузка — это не слабость и не роскошь, а нормальная часть работы управленца. Особенно если человек отвечает за сложные решения.Поэтому Байкал в
Когда человек несколько дней находится в плотной профессиональной среде, обсуждает проекты, решения, ограничения, сравнивает подходы, смотрит на работающие системы, у него постепенно возникает потребность в дистанции. В паузе, в пространстве, где можно не просто переключиться, а собрать для себя главное.Именно поэтому Байкал для меня — часть его внутренней логики. Не потому, что «красиво». Хотя, конечно, красиво. А потому, что сильные выводы не всегда рождаются в аудитории — иногда им нужно пространство, воздух и тишина.Мне вообще кажется, что профессиональная перезагрузка — это не слабость и не роскошь, а нормальная часть работы управленца. Особенно если человек отвечает за сложные решения.Поэтому Байкал в 




 Источник:
Источник: Мы в
Мы в  #импортозависимость
#импортозависимость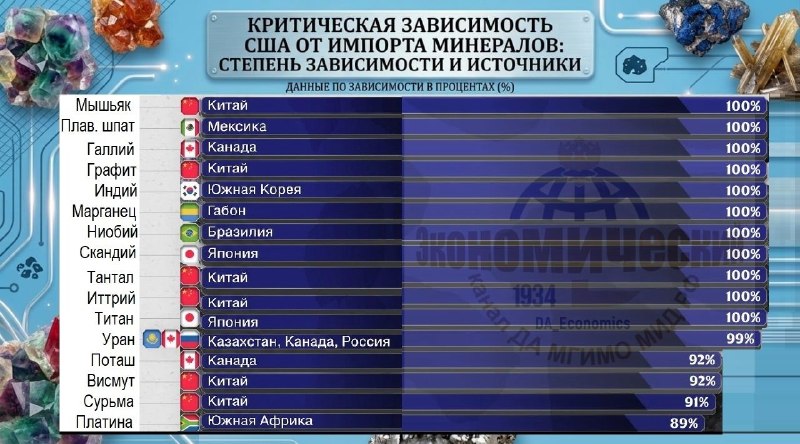



 На самом деле ничего не лучше, это просто две разные процедуры перехода права, одна - при жизни, другая - после смерти. Сравнивать сложно, но давайте разберем все плюсы и минусы, может это поможет принять решение в вашем случае
На самом деле ничего не лучше, это просто две разные процедуры перехода права, одна - при жизни, другая - после смерти. Сравнивать сложно, но давайте разберем все плюсы и минусы, может это поможет принять решение в вашем случае Договор дарения
Договор дарения






