[1/3] System Design. Подготовка к сложному интервью по GenAI (Рубрика #SystemDesign)Изучил интересную
книгу для подготовки к интервью по System Design, но уже в новой реальности, когда проектировать надо не только базы, очереди, кэши и микросервисы, но и системы вокруг LLM, diffusion models, RAG, мультимодальных моделей и AI-powered продуктов. Это русское издание книги "
Generative AI System Design Interview" из экосистемы ByteByteGo. Авторы - Али Аминиан и Хао Шенг. Али Аминиан уже известен по книге про ML System Design Interview, а здесь фокус смещается с классических ML-систем вроде поиска и рекомендаций на генеративный AI: чатботы, генерацию текста, изображений, видео, RAG и персонализированные AI-сценарии.
В обычном System Design Interview кандидат часто рисует распределенную систему: API, балансировщики, базы данных, очереди, кэши, фоновые джобы, мониторинг. В GenAI-интервью все это остается, но появляется еще один слой сложности:
- Какие данные нужны;
- Какую модель выбрать;
- Нужен ли RAG или fine-tuning;
- Как измерять качество генерации;
- Как бороться с hallucinations;
- Как учитывать latency и стоимость инференса;
- Как встроить safety-фильтры;
- Как собирать feedback loop;
- Как мониторить деградацию системы после запуска.
Именно поэтому книга полезна не только ML-инженерам. Она хорошо ложится и на backend engineers, и на архитекторов, и на технических руководителей, которым сейчас приходится проектировать AI-фичи не как демо на API, а как часть production-системы.
Внутри книги заявлены три главные вещи:
1️⃣ Фреймворк из 7 шагов для GenAI System DesignАвторы предлагают не начинать сразу с "берем LLM и векторную базу данных", а последовательно пройти путь от требований до деплоя и мониторинга в проде. Это сильно дисциплинирует мышление, потому что в GenAI-задачах легко перепрыгнуть к модной технологии и забыть про реальные ограничения продукта.
2️⃣ 10 практических задач с подробными решениямиСреди кейсов есть следующие: Gmail Smart Compose, Google Translate, ChatGPT-like personal assistant, Image Captioning, Retrieval-Augmented Generation, Realistic Face Generation, High-Resolution Image Synthesis, Text-to-Image Generation, Personalized Headshot Generation и Text-to-Video Generation. Этот набор покрывает разные сценарии и сильно шире, чем просто прикрутить трансформер к чат-боту:)
3️⃣ Много диаграмм и end-to-end разборовДля System Design это особенно важно. Хороший ответ на интервью - это не только "какую модель выбрать", но и то, как выглядит система вокруг модели: preprocessing, retrieval, prompt builder, inference service, post-processing, safety layer, logging, monitoring, feedback loop. Мне кажется, главная ценность книги в том, что она показывает: "GenAI-система - это не модель в вакууме".
В общем, модель - это конечно ядро, но вокруг него есть данные, права доступа, индексы, промпты, ранжирование, guardrails, UX, стоимость, GPU-инфраструктура, A/B-тесты, метрики качества и эксплуатационные ограничения. И если все это не проектировать осознанно, то на выходе получается не production-система, а красивый прототип с непредсказуемым поведением.
Книга полезна как способ обновить представление о System Design в эпоху AI, ведь раньше мы проектировали в основном детерминированный софт: запрос пришел, сервис обработал, база ответила, результат вернулся. Теперь все чаще приходится проектировать системы с вероятностным поведением: модель может ответить хорошо, средне, неверно, опасно, дорого или слишком медленно. Поэтому архитектура должна включать не только масштабирование и отказоустойчивость, но и evaluation, safety, feedback и постоянный контур улучшения.
В
продолжении более подробный разбор фреймворка в 7 шагов от авторов книги.
#SystemDesign #AI #GenAI #Architecture #Engineering #ML #Interview #Software









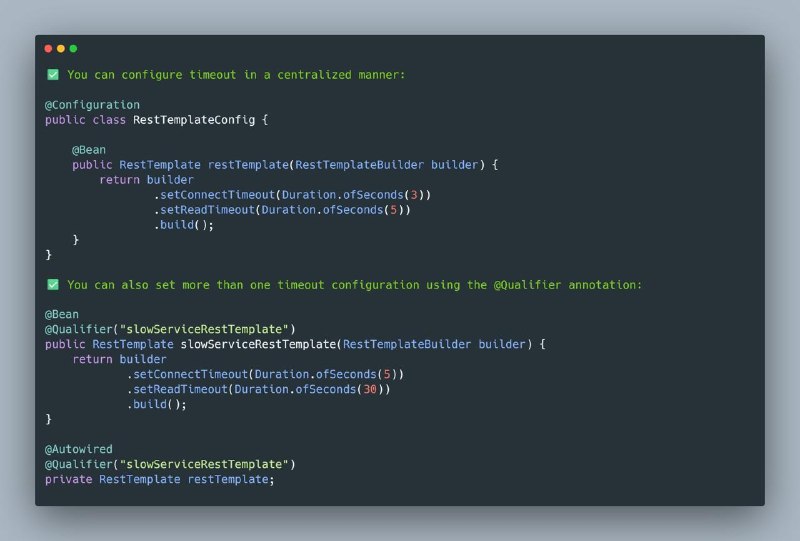













 Claude - это инструмент, который может писать тексты, разбирать документы, работать с файлами, суммировать большие PDF, помогать с кодом и автоматизировать рутину.Но главная ошибка новичков - использовать Claude как обычный поиск: задали короткий вопрос, получили средний ответ и закрыли вкладку.Нужно иначе.Дайте ему контекст. Покажите примеры. Объясните, какой результат нужен. Загрузите файл, папку или длинный документ. Попросите не просто ответить, а подумать, сравнить варианты и выдать готовое решение.Claude особенно хорош там, где нужно много читать, аккуратно писать и не терять логику на длинной дистанции.Начните с трёх задач: перескажите большой PDF, перепишите текст в вашем стиле и попросите разобрать папку с файлами.И продвинутый совет: заведите отдельный файл ABOUT_ME.md, где будут ваша роль, аудитория, стиль, запреты и примеры хороших ответов. Загружайте его в начале работы - и Claude будет отвечать не «вообще нормально», а ближе к вашему реальному стилю.После этого Claude перестаёт быть игрушкой и становится рабочим напарником.
Claude - это инструмент, который может писать тексты, разбирать документы, работать с файлами, суммировать большие PDF, помогать с кодом и автоматизировать рутину.Но главная ошибка новичков - использовать Claude как обычный поиск: задали короткий вопрос, получили средний ответ и закрыли вкладку.Нужно иначе.Дайте ему контекст. Покажите примеры. Объясните, какой результат нужен. Загрузите файл, папку или длинный документ. Попросите не просто ответить, а подумать, сравнить варианты и выдать готовое решение.Claude особенно хорош там, где нужно много читать, аккуратно писать и не терять логику на длинной дистанции.Начните с трёх задач: перескажите большой PDF, перепишите текст в вашем стиле и попросите разобрать папку с файлами.И продвинутый совет: заведите отдельный файл ABOUT_ME.md, где будут ваша роль, аудитория, стиль, запреты и примеры хороших ответов. Загружайте его в начале работы - и Claude будет отвечать не «вообще нормально», а ближе к вашему реальному стилю.После этого Claude перестаёт быть игрушкой и становится рабочим напарником.
