Highload
Провёл вчера 7 (семь!) часов подряд на одном созвоне.
Последний раз такое было в Яндексе, только еще до удаленки, а просто в офисе с командой.
Постоянно так жить, конечно, не хватит никаких сил и энергии, но как разовый подвиг можно.
Зато, за эти семь часов заставили тачку из 8xH100 запотеть в полную силу, а там, на минуточку:
- 640Gb видеопамяти
- 135k CUDA ядер
- 4k тензорных ядер
И всё это роскошество лежало с утилизацией в 100%, снижая нагрузку только на доли секунды, в моменте переключения задач внутри очереди.
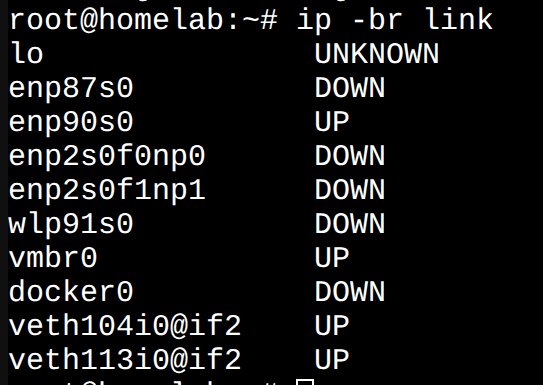
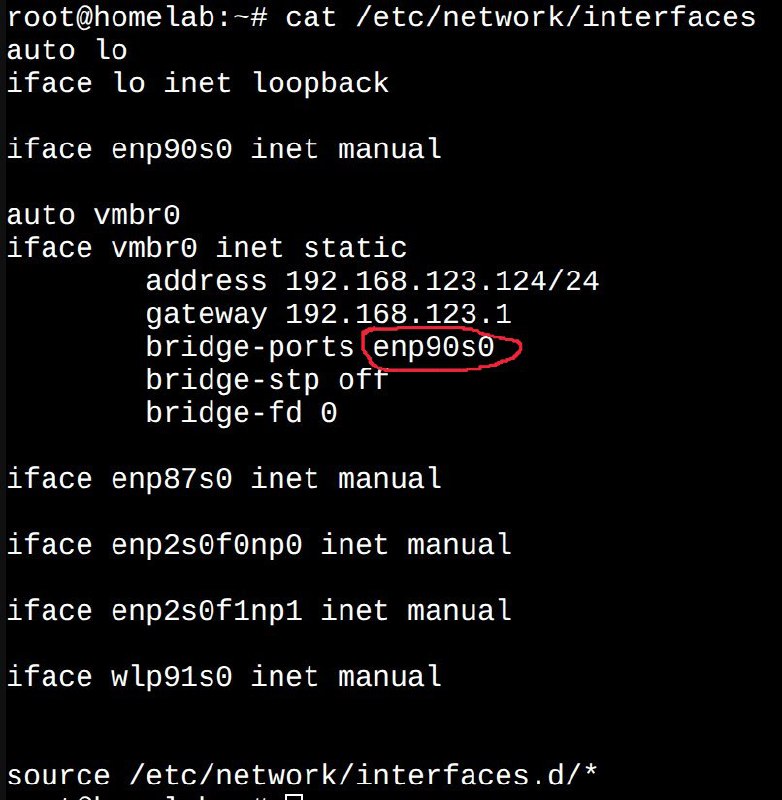
По дороге разобрался, как на огромных серверах разводятся ресурсы и доступ к ним – если коротко, то очень интересно.
Интересно потому, что там:
- Несколько сокетов с процессорами
- Каждый серверный процессор, это на самом деле несколько гражданских процессоров под одной крышкой, и там они называются чиплеты
- Каналы памяти и шины до GPU подведены к конкретным сокетам
Всё это подводит нас к тому, что можно конечно дергать с любого ядра любую память/любой GPU, но...
Если не проверить, что куда физически разведено, то один CPU может пойти в RAM/GPU от другого CPU, и это будет межпроцессорное взаимодействие, по объездной дороге, медленно.
И всё вместе это называется
NUMA (non-uniform memory access) – хотя на мой взгляд, этот термин не отражает всей полноты, так как это не только про память, но и про другие особенности архитектуры и шины.
Обожаю, короче, колупаться в серваках и линуксах, да)))



 LMS — Learning Management System — система для онлайн-обучения, где можно размещать курсы, тесты, отслеживать прогресс студентов. Пример:
LMS — Learning Management System — система для онлайн-обучения, где можно размещать курсы, тесты, отслеживать прогресс студентов. Пример: 




![Уехал - Охуел [эмигрирую и рефлексирую]](/api/media/avatar/uehal_ohuel)
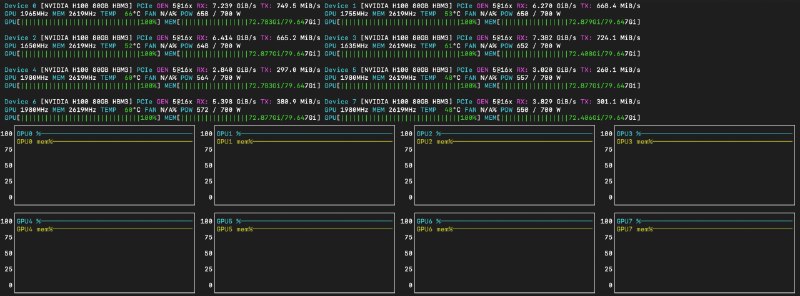



 Как хостинг влияет на скорость сайта? Наши замерыМы провели небольшое тестирование: проверили, как на одном и том же сайте на WordPress 6.5 (без изменений в коде) ведут себя разные хостинги и VDS, если замерять через Google Lighthouse.Тест длился неделю. Каждый день — новое измерение, один и тот же регион: Дальний Восток.Важно: это не реклама и не антиреклама. Просто делимся своими цифрами.
Как хостинг влияет на скорость сайта? Наши замерыМы провели небольшое тестирование: проверили, как на одном и том же сайте на WordPress 6.5 (без изменений в коде) ведут себя разные хостинги и VDS, если замерять через Google Lighthouse.Тест длился неделю. Каждый день — новое измерение, один и тот же регион: Дальний Восток.Важно: это не реклама и не антиреклама. Просто делимся своими цифрами. Что смотрели?FCP (First Contentful Paint) — первая отрисовка видимого контентаLCP (Largest Contentful Paint) — когда появляется основной блокTBT (Total Blocking Time) — как долго сайт «тормозит» после загрузкиCLS (Cumulative Layout Shift) — насколько дергается макетSpeed Index — насколько быстро появляется контент в целом. Общий Lighthouse Score.
Что смотрели?FCP (First Contentful Paint) — первая отрисовка видимого контентаLCP (Largest Contentful Paint) — когда появляется основной блокTBT (Total Blocking Time) — как долго сайт «тормозит» после загрузкиCLS (Cumulative Layout Shift) — насколько дергается макетSpeed Index — насколько быстро появляется контент в целом. Общий Lighthouse Score.  Вывод:Разница между хостингами может быть огромной — до 3 секунд по LCP и в 3 раза по общему индексу скорости. Это влияет и на SEO, и на поведение пользователей.Сайт может выглядеть одинаково, но работать по-разному — только из-за хостинга.Если у тебя есть сайт, который грузится медленно — возможно, дело не в нём, а в сервере.
Вывод:Разница между хостингами может быть огромной — до 3 секунд по LCP и в 3 раза по общему индексу скорости. Это влияет и на SEO, и на поведение пользователей.Сайт может выглядеть одинаково, но работать по-разному — только из-за хостинга.Если у тебя есть сайт, который грузится медленно — возможно, дело не в нём, а в сервере.