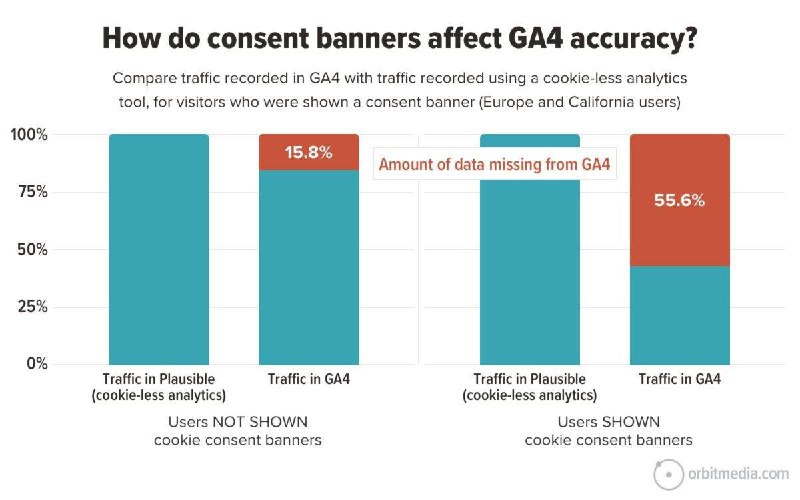
⬆ 2/2Похожим образом будет работать и наша модель, с той разницей, что контролер принимает свои решения подсознательно, а модель абсолютно четко осознает, на сколько % она уверена в качестве того или иного продукта, и какую точку на графике метрик нужно выбрать с учетом заданных штрафов. Цена неточных вводных Приступим, наконец, к расчетам, и посмотрим, к чему будут приводить погрешности в понимании бизнес-последствий в самом простейшем случае. Дано: - метрики разработанной модели соответствуют графику выше, математически он описывается уравнением x * y = 100; - на производстве 4% реального брака (и 96% качественной продукции) - издержки от отправленного клиенту брака - 1000 руб./шт. - издержки доп. контроля от неверно отбракованного качественного товара - 10 руб./шт. При таких вводных оптимальное решение (x = 4,9%; y = 20,4%) дает общие ожидаемые издержки 3,92 руб. на единицу продукции. Кому интересно - математика кейса во вложении. Давайте посмотрим на типичные грабли, по которым тут можно пройтись, и их последствия: 1. Использование базового подхода "просто хотим максимально редко ошибаться" Результат: x = 49%; y = 2,04%, общие издержки 19,79 руб./шт., то есть в 5 раз больше оптимальных, лишние издержки составят более 400%. Довольно очевидно, что этот факт - результат того, что один из типов ошибки в 100 раз дороже другого. Насколько это будет важно при меньших соотношениях? Вот немного цифр: - при соотношении 14 к 1 лишние потери в издержках будут составлять 100% - при соотношении всего 7 к 1 - 51% - наконец, если одна ошибка дороже другой всего в 2 раза, бизнес потеряет 6,1% В реальных задачах часто встречается ситуация, когда последствия разных ошибок отличаются во много раз, поэтому борьба идет за десятки и сотни процентов эффекта. 2. Неточность в оценке издержек Например, мы забыли, что контролер стоит компании не просто расходов на зарплату, но еще и расходов на рабочее место, дмс, налогов и т.п. Это примерно в 2 раза увеличивает издержки от его проверок - вместо реальных 10 руб./шт. мы заложили в расчет 5 руб./шт. Результат: x = 3,46%; y = 28,87%, общие издержки 4,16 руб./шт. - потери есть, но гораздо меньше, всего на 6% хуже оптимума. Впрочем, безусловно, даже за 6% снижения издержек все равно стоит побороться. 3. Неточность в оценке реальной доли дефектов Например, мы почему-то считали, что у нас не 4% брака, а 2,5%, и заложили это в расчеты. Результат: x = 6,2%; y = 16%, общие издержки 4,04 руб./шт. - потери всего 3%, то есть наш кейс почти не изменяется от этого. На этом очень упрощенном примере видно, что неточность во вводных проекта приводит не только к неточности "на бумаге" при защите проекта - в отличие от обычных проектов, она также ведет и к разработке реально другой системы, и к другим результатам на выходе из проекта. Делает ли это проекты сложнее? Безусловно. Значит ли это, что игра не стоит свеч? Конечно, нет, ведь речь зачастую идет об огромных потенциальных эффектах - но важно понимать эти риски и работать с ними.#AI #метрики