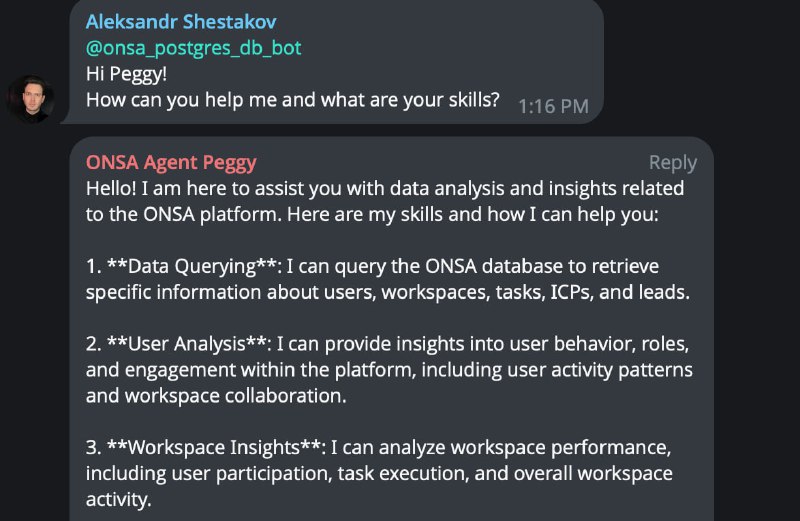
Автоматизированная сквозная аналитикаМы очень любим цифры и данные, потому что только на их основе можно принимать правильные решения. В перформанс-маркетинге важен не только первый клик, а весь путь клиента.
Часто один клиент проходит 10+ точек касания: реклама → квиз → звонок → емейл → WhatsApp → повторный звонок → оплата. Без нормальной атрибуции (= понимания вклада каждого из каналов в цепочке) маркетинг работает вслепую.
Мы у себя в немецком стартапе стали изучать вопрос сквозной аналитики и собрали крутейшую систему с помощью Севы Устинова и его продукта Elly Analytics.
Как это работает:
1. Сбор данныхПодключили все источники: рекламные кабинеты, CRM, мессенджеры, емейл-сервисы.
Каждый клик, звонок и сообщение теперь фиксируется в одном месте.
2. Полная история клиентаДля каждого лида строится customer profile — от первого касания до оплаты.
Видим, через какие каналы и точки он прошёл, сколько времени занял цикл сделки.
3. Мульти-тач атрибуцияСчитаем вклад каждого канала в финальный результат. Теперь видно: (а) какие источники реально приводят клиентов, (б) где бюджет сжигается
4. LTV-прогнозыДля длинных циклов сделки смотрим не только стоимость лида, но и то, какие клиенты окупаются через недели или месяцы. Это меняет стратегию закупки — деньги уходят в источники с высоким LTV.
Раньше уходило 5–6 часов в неделю на ручную сборку отчётов в Excel. Теперь все данные в одном месте за пару кликов, нет расхождений, ручных загрузок и обновлений данных и мы быстрее принимаем решения по креативам и бюджетам
Примеры отчетов→
Отчет с демо данными на примере реального B2C subscription бизнеса→
Когортный отчет — показывает качество клиентов по каналам и прогноз LTV – с помощью него можно увидеть источники с лучшим ретеншеном и правильно спланировать баинг
→
Main Report — сквозной отчет со всеми метриками и каналами в динамике – именно с него начинается каждое утро перформанс команд
→
Overview — отчет для CMO и команды, чтобы знать, как идут дела
→
Ссылка на лум-экскурсию по отчетам.
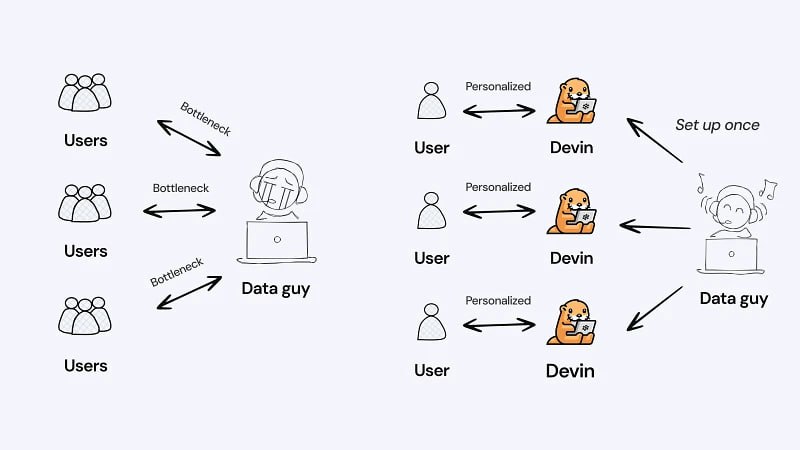
Как уже совсем скоро будет выглядеть аналитика с AI агентом 
AI показывает план → вы утверждаете → агент выполняет
Под капотом: дата-фаундейшн с мульти-тач атрибуцией, стримингом из любых баз данных, автогенерация правил для рекламы и агенты, которые анализируют данные и объясняют, почему изменились метрики. Вы разговариваете с чатом простым языком, решаете маркетинговые задачи, в все технические берет на себя агент.
В результате: можно тестировать в 10 раз больше гипотез и автоматизировать до 90% ручных задач. Особенно эффективно работает с EdTech, HealthTech, FinTech, недвижимостью, B2B SaaS и subscription-бизнесами — там, где длинные воронки, сложные touchpoints (звонки, квизы, чат-боты) и длинный хвост LTV.
Elly Analytics скоро релизят Vibe-маркетинг платформу для user acquisition команд - заходите посмотреть как это будет выглядеть.
Сохраняйте себе пост и перешлите друзьям, кому актуально!
🔥Если хотите первыми узнавать про апдейты того, как можно настраивать аналитику (и еще Cursor) - залетайте на
канал Севы Устинова, он пишет много чего интересного по теме AI.
И кстати Сева будет рассказывать про аналитику (и про Cursor) супер подробно на курсе
Ninja Marketing. А мы сегодня как раз закрываем набор на новый поток этого курса и следующий поток будет не раньше следующего года!
На программе за 6 месяцев вы погрузитесь в 6 каналов трафика, получите рабочие фреймворки, воронки, кейсы и лучшие практики этого года и научитесь строить отдел AI маркетологов. Последняя возможность вписаться по ссылке:
https://solokumi.com/course_ninjamarketing 



 Минимальная дата в формате
Минимальная дата в формате