Окей, в стандартных отчетах Метрики данные с Директом не сходятся. Но в отчёте «Директ, Расходы» всё сходиться с «Мастером отчётов» должно? Давайте разбираться.
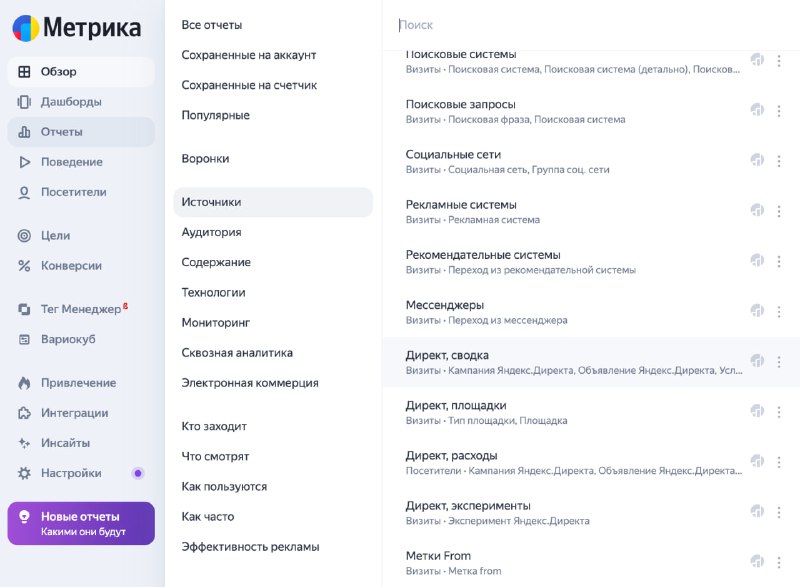
Действительно, логика группы отчётов по Директу в Метрике отличается (в группу входят «Директ, Сводка», «Директ, Площадки», «Директ, Расходы» и «Директ, эксперименты» — скриншот №1).
Здесь статистика основана на учтенных кликах — кликах, которые прошли проверку системой защиты от фрода в Директе. Визиты, вызванные кликами, не прошедшими проверку, не попадают в эту группу отчётов.
Это значит, что:— В этих отчётах визитов будет меньше, чем в других отчетах Метрики (вычитаем те, что были вызваны аннулированными кликами)
— Но количество визитов всё равно может отличаться от количества кликов в Директе (некоторые клики могли не вызвать визит, либо вызвать несколько визитов).
Почему клик в Директе может не вызвать визит в Метрике:• Посетитель закрыл страницу сайта до того, как загрузился счетчик
• Номер счетчика не указан в настройках кампании Директа
• В браузере или ОС пользователя работает блокировщик рекламы, плагин или антивирус, запрещающий загрузку счетчиков
• На сайте установлен циклический редирект
• Иные технические проблемы
Какие еще могут быть расхождения между группой отчётов по Директу в Метрике и самим Директом:✔️В Метрике отображаются кампании Директа, которые есть на логине, под которым вы просматриваете отчет, и кампании, к которым у логина есть представительский доступ.
✔️В Метрике содержится информация о расходах на кампании Директа с оплатой за клики или конверсии. Расходы рекламных кампаний с оплатой за показы не отображаются.
✔️В Метрике отображаются данные по кампаниям, объявления которых ведут на сайт (не в мобильное приложение).
✔️В Метрике расходы отображаются без учета НДС. В Директе — в зависимости от заданных вами настроек.
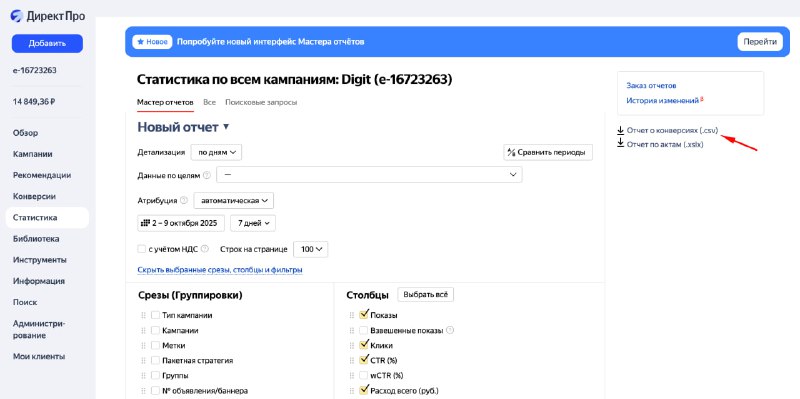
✔️Данные о расходах Метрика привязывает к дате клика. Директ в «Мастере отчётов» тоже. Но в «Отчёте о конверсиях» (что это такое — смотрите на скриншоте №2) расход для кампаний с оплатой за конверсии считается на дату совершения конверсии.
✔️Метрика получает данные о кликах и расходах и сопоставляет их с данными о визитах за выбранный период. Поэтому часть данных может не войти в заданный период. Это зависит от модели атрибуции, которая используется в отчёте.
Например:
1 октября Вася перешел на сайт по объявлению Директа.10 октября Вася вернулся из закладок и оставил заявку.
Смотрим отчет «Директ, расходы», период — 1-9 октября. Атрибуция «Последний переход из Директа» → Мы не увидим визит с конверсией, поскольку он состоялся позже рассматриваемого периода.
Смотрим тот же отчет и той же атрибуцией, период — 1-10 октября → Наш визит с конверсией уже попадает в рассматриваемый период. Источник у него будет определен, как «Переход из Директа». Несмотря на то, что посетитель попал на сайт «Прямым заходом».
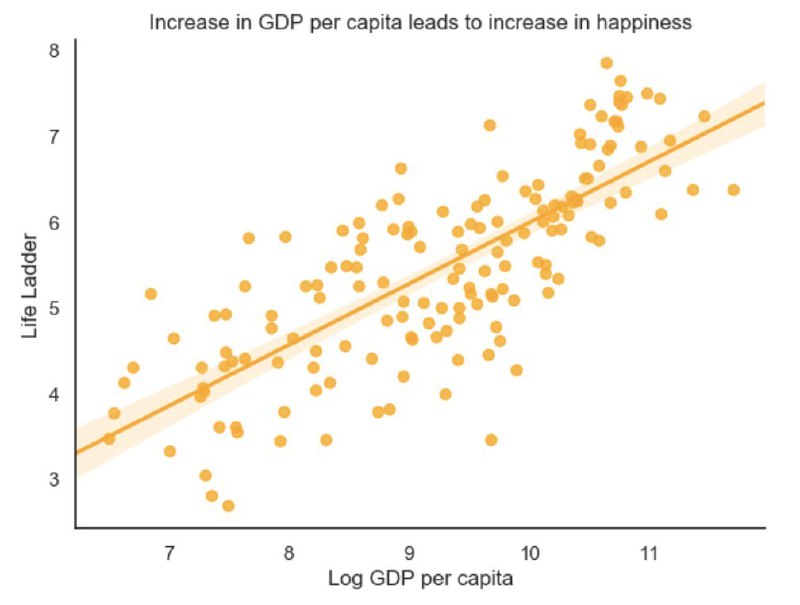
Надеюсь, удалось понятно разложить. Еще подробнее — на грядущем курсе по Метрике👌🏻  Топ. Как создавать наглядные графики в PythonПодробное руководство по визуализации данных в Python. В нем мы рассказали про построение графиков при помощи библиотек Pandas, Seaborn и Plotly.#топ
Топ. Как создавать наглядные графики в PythonПодробное руководство по визуализации данных в Python. В нем мы рассказали про построение графиков при помощи библиотек Pandas, Seaborn и Plotly.#топ